您现在的位置是:网站首页> 编程开发> java 编程开发
记录一次阿里云pod里oom的排查和解决
![]() 2022-06-22【java】
1928人已围观
2022-06-22【java】
1928人已围观
简介 今天生产环境上的pod一直在重新,以我的经验来看,肯定是产生大量的fullgc导致,后来打开cat去看了一下记录。 上图是后补的,只有一个fullgc的记录了。查找问题之前有多次fullgc,且时间都是10秒以上的,这是灾难啊。 首先我猜猜出现fullgc的情况有哪些吧,第一个机率 是最大的

记录一次阿里云pod里oom的排查和解决
最后更新:2022-06-22 16:45:58
推荐指数:
今天生产环境上的pod一直在重新,以我的经验来看,肯定是产生大量的fullgc导致,后来打开cat去看了一下记录。
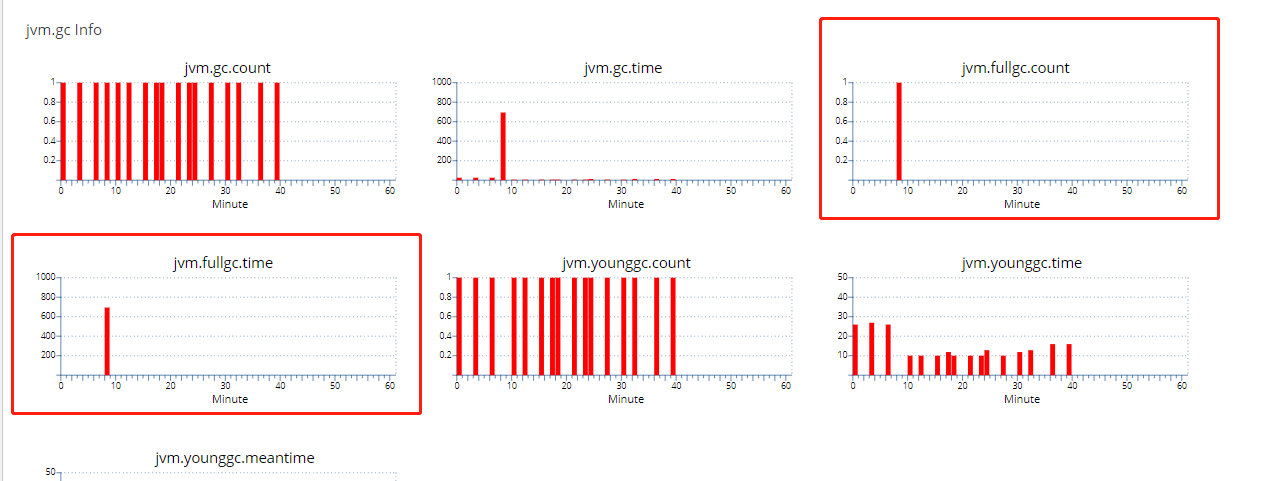
上图是后补的,只有一个fullgc的记录了。查找问题之前有多次fullgc,且时间都是10秒以上的,这是灾难啊。
首先我猜猜出现fullgc的情况有哪些吧,第一个机率 是最大的,就从这里入手。
|
# |
类别 |
示例 |
说明 |
解决方案 |
|---|---|---|---|---|
| 1 | 大对象 | 一次性加载大量数据到内存(未做分页处理) |
大对象超过 -XX:PretenuereSzieThreshoild参数的值, 直接进入老年代。 老年代内存使用率达到阈值会触发FullGC。 |
|
| 2 | JVM参数设置不合理 | 未指定JVM参数 | JVM启动后现申请很小的内存空间,并动态调整,从而触发FullGC。 |
根据实际业务需求,设置JVM参数
|
| 3 | 代码或框架调用System.gc() | Tomcat6会一小时调用一次 |
|
|
| 4 | 内存泄漏 | 程序bug,超大日志 |
日志超过阿里云日志阈值,被死锁。 线程死锁,未设置超时等。一直泄漏会频繁触发FullGC,并最终导致OOM |
|
追加以下JVM参数,配置独立的GC日志文件:
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=64m
|
分析现象:
-
线上环境POD中使用jmap -histo:live 7 命令触发fullgc后,oldgen使用内存量仍然没有明显的下降。
排查步骤:
-
线上环境POD中,使用jmap -histo 7,做简单的业务对象排查。
-
线上环境POD中,使用jmap -dump:format=b,file=heapdump.phrof 7, 将java内存堆栈保存到文件。
-
线上环境POD中,使用zip命令压缩文件,heapdump.zip。
-
线上环境aliyun cloudshell中,使用kubectl cp ${pod id}:heapdump.zip ./heapdump.zip,复制到aliyun cloudshell。
-
从线上环境aliyun cloudshell下载heapdump.zip。
-
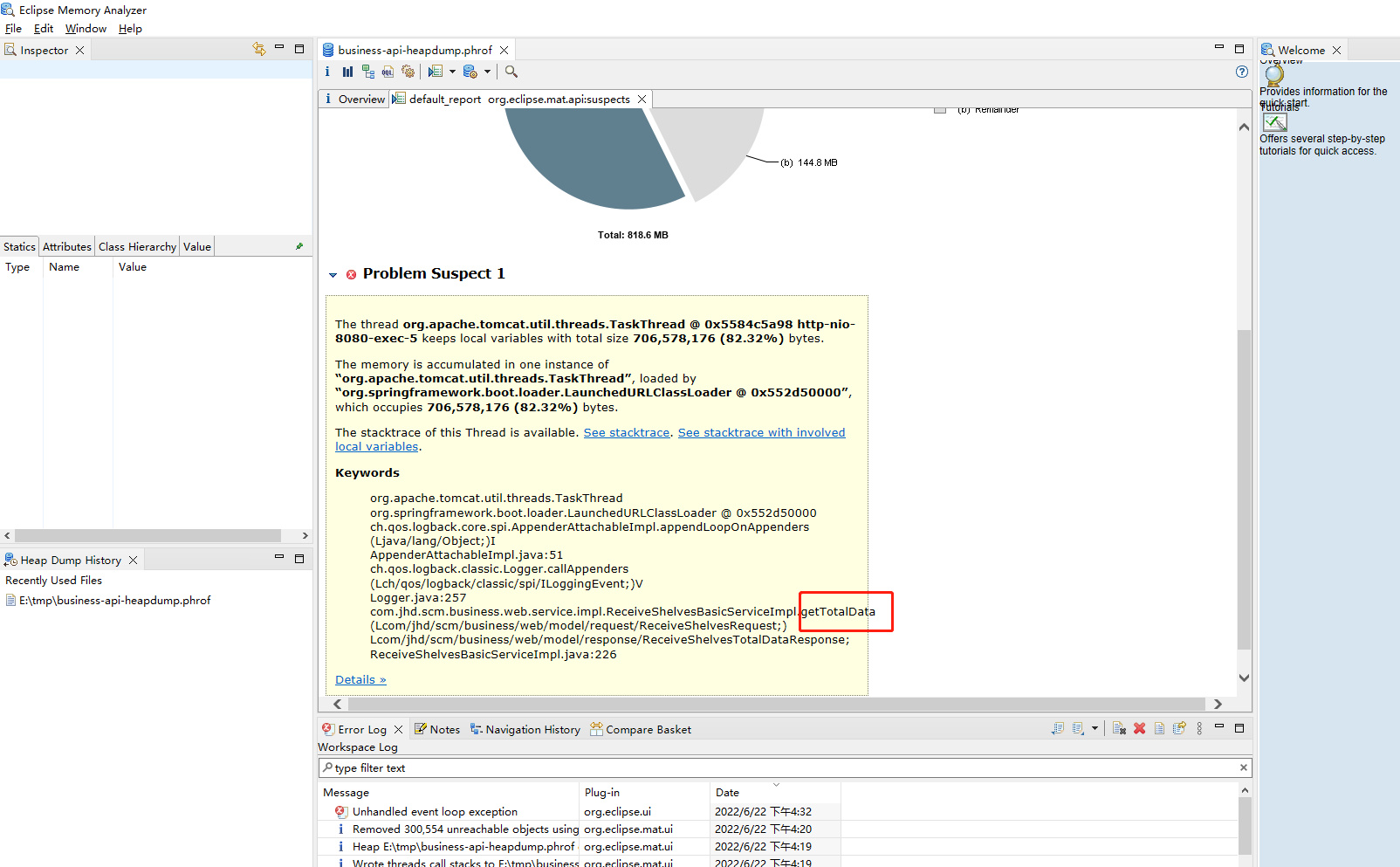
使用MAT分析dump文件,找到可能泄漏的大对象,发现是日志输出大量数据时被com.aliyun.openservices.log.logback.LoghubAppender的memPoolSizeInByte限制锁定,无法完成日志输出处理。
解决方案:
-
临时关闭接口返回值的日志。
-
优化接口设计,限制一次获取数据的数量。
最后问题的排查,打开后第一个出现了大内存,接下来去分析代码,结果 发现果然 是这里的问题。
很赞哦! (0)
下一篇:java 常见面试题
文章评论
验证码:










